Locating HTML elements with Node.js
In this lesson we'll locate product data in the downloaded HTML. We'll use Cheerio to find those HTML elements which contain details about each product, such as title or price.
In the previous lesson we've managed to print text of the page's main heading or count how many products are in the listing. Let's combine those two. What happens if we print .text() for each product card?
import * as cheerio from 'cheerio';
const url = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $(".product-item").toArray()) {
console.log($(element).text());
}
} else {
throw new Error(`HTTP ${response.status}`);
}
Calling toArray() converts the Cheerio selection to a standard JavaScript array. We can then loop over that array and process each selected element.
Cheerio requires us to wrap each element with $() again before we can work with it further, and then we call .text(). If we run the code, it… well, it definitely prints something…
$ node index.js
JBL
JBL Flip 4 Waterproof Portable Bluetooth Speaker
Black
+7
Blue
+6
...
To get details about each product in a structured way, we'll need a different approach.
Locating child elements
As in the browser DevTools lessons, we need to change the code so that it locates child elements for each product card.
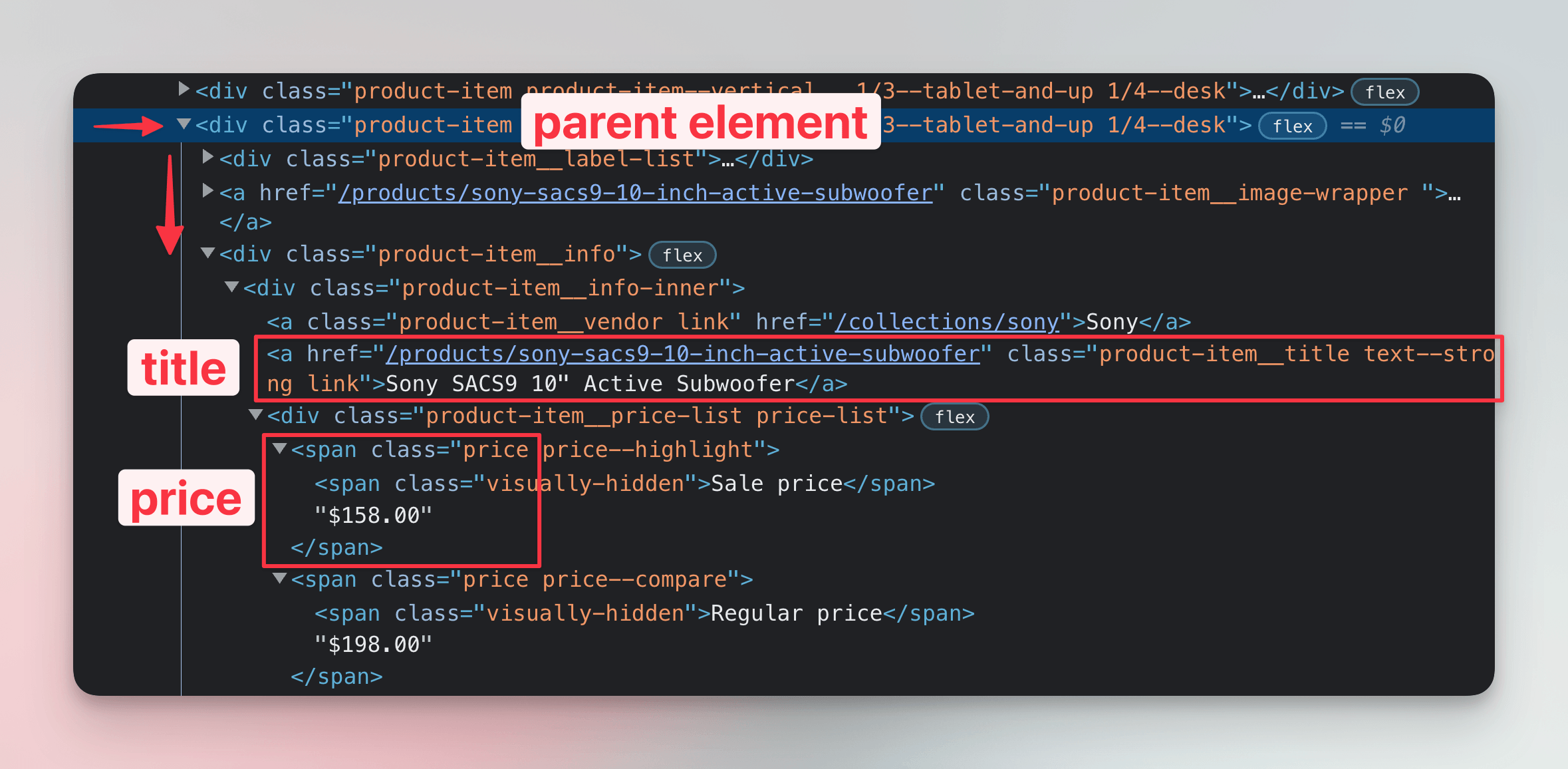
We should be looking for elements which have the product-item__title and price classes. We already know how that translates to CSS selectors:
import * as cheerio from 'cheerio';
const url = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $(".product-item").toArray()) {
const $productItem = $(element);
const $title = $productItem.find(".product-item__title");
const title = $title.text();
const $price = $productItem.find(".price");
const price = $price.text();
console.log(`${title} | ${price}`);
}
} else {
throw new Error(`HTTP ${response.status}`);
}
Let's run the program now:
$ python main.py
JBL Flip 4 Waterproof Portable Bluetooth Speaker |
Sale price$74.95
Sony XBR-950G BRAVIA 4K HDR Ultra HD TV |
Sale priceFrom $1,398.00
...
There's still some room for improvement, but it's already much better!
In jQuery and Cheerio, the core idea is a collection that wraps selected objects, usually HTML elements. To tell these wrapped selections apart from plain arrays, strings or other objects, it's common to start variable names with a dollar sign. This is just a naming convention to improve readability. The dollar sign has no special meaning and works like any other character in a variable name.
Precisely locating price
In the output we can see that the price isn't located precisely. For each product, our scraper also prints the text Sale price. Let's look at the HTML structure again. Each bit containing the price looks like this:
<span class="price">
<span class="visually-hidden">Sale price</span>
$74.95
</span>
When translated to a tree of JavaScript objects, the element with class price will contain several nodes:
- Textual node with white space,
- a
spanHTML element, - a textual node representing the actual amount and possibly also white space.
We can use Cheerio's .contents() method to access individual nodes. It returns a list of nodes like this:
LoadedCheerio {
'0': <ref *1> Text {
parent: Element { ... },
prev: null,
next: Element { ... },
data: '\n ',
type: 'text'
},
'1': <ref *2> Element {
parent: Element { ... },
prev: <ref *1> Text { ... },
next: Text { ... },
children: [ [Text] ],
name: 'span',
type: 'tag',
...
},
'2': <ref *3> Text {
parent: Element { ... },
prev: <ref *2> Element { ... },
next: null,
data: '$74.95',
type: 'text'
},
length: 3,
...
}
It seems like we can read the last element to get the actual amount. Let's fix our program:
import * as cheerio from 'cheerio';
const url = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $(".product-item").toArray()) {
const $productItem = $(element);
const $title = $productItem.find(".product-item__title");
const title = $title.text();
const $price = $productItem.find(".price").contents().last();
const price = $price.text();
console.log(`${title} | ${price}`);
}
} else {
throw new Error(`HTTP ${response.status}`);
}
We're enjoying the fact that Cheerio selections provide utility methods for accessing items, such as .first() or .last(). If we run the scraper now, it should print prices as only amounts:
$ node index.js
JBL Flip 4 Waterproof Portable Bluetooth Speaker | $74.95
Sony XBR-950G BRAVIA 4K HDR Ultra HD TV | From $1,398.00
...
Great! We have managed to use CSS selectors and walk the HTML tree to get a list of product titles and prices. But wait a second—what's From $1,398.00? One does not simply scrape a price! We'll need to clean that. But that's a job for the next lesson, which is about extracting data.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Scrape Wikipedia
Download Wikipedia's page with the list of African countries, use Cheerio to parse it, and print short English names of all the states and territories mentioned in all tables. This is the URL:
https://en.wikipedia.org/wiki/List_of_sovereign_states_and_dependent_territories_in_Africa
Your program should print the following:
Algeria
Angola
Benin
Botswana
Burkina Faso
Burundi
Cameroon
Cape Verde
Central African Republic
Chad
Comoros
Democratic Republic of the Congo
Republic of the Congo
Djibouti
...
Solution
import * as cheerio from 'cheerio';
const url = "https://en.wikipedia.org/wiki/List_of_sovereign_states_and_dependent_territories_in_Africa";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const tableElement of $(".wikitable").toArray()) {
const $table = $(tableElement);
const $rows = $table.find("tr");
for (const rowElement of $rows.toArray()) {
const $row = $(rowElement);
const $cells = $row.find("td");
if ($cells.length > 0) {
const $thirdColumn = $($cells[2]);
const $link = $thirdColumn.find("a").first();
console.log($link.text());
}
}
}
} else {
throw new Error(`HTTP ${response.status}`);
}
Because some rows contain table headers, we skip processing a row if table_row.select("td") doesn't find any table data cells.
Use CSS selectors to their max
Simplify the code from previous exercise. Use a single for loop and a single CSS selector.
You may want to check out the following pages:
Solution
import * as cheerio from 'cheerio';
const url = "https://en.wikipedia.org/wiki/List_of_sovereign_states_and_dependent_territories_in_Africa";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $(".wikitable tr td:nth-child(3)").toArray()) {
const $nameCell = $(element);
const $link = $nameCell.find("a").first();
console.log($link.text());
}
} else {
throw new Error(`HTTP ${response.status}`);
}
Scrape F1 news
Download Guardian's page with the latest F1 news, use Cheerio to parse it, and print titles of all the listed articles. This is the URL:
https://www.theguardian.com/sport/formulaone
Your program should print something like the following:
Wolff confident Mercedes are heading to front of grid after Canada improvement
Frustrated Lando Norris blames McLaren team for missed chance
Max Verstappen wins Canadian Grand Prix: F1 – as it happened
...
Solution
import * as cheerio from 'cheerio';
const url = "https://www.theguardian.com/sport/formulaone";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $("#maincontent ul li h3").toArray()) {
console.log($(element).text());
}
} else {
throw new Error(`HTTP ${response.status}`);
}