Scraping product variants with Node.js
In this lesson, we'll scrape the product detail pages to represent each product variant as a separate item in our dataset.
We'll need to figure out how to extract variants from the product detail page, and then change how we add items to the data list so we can add multiple items after scraping one product URL.
Locating variants
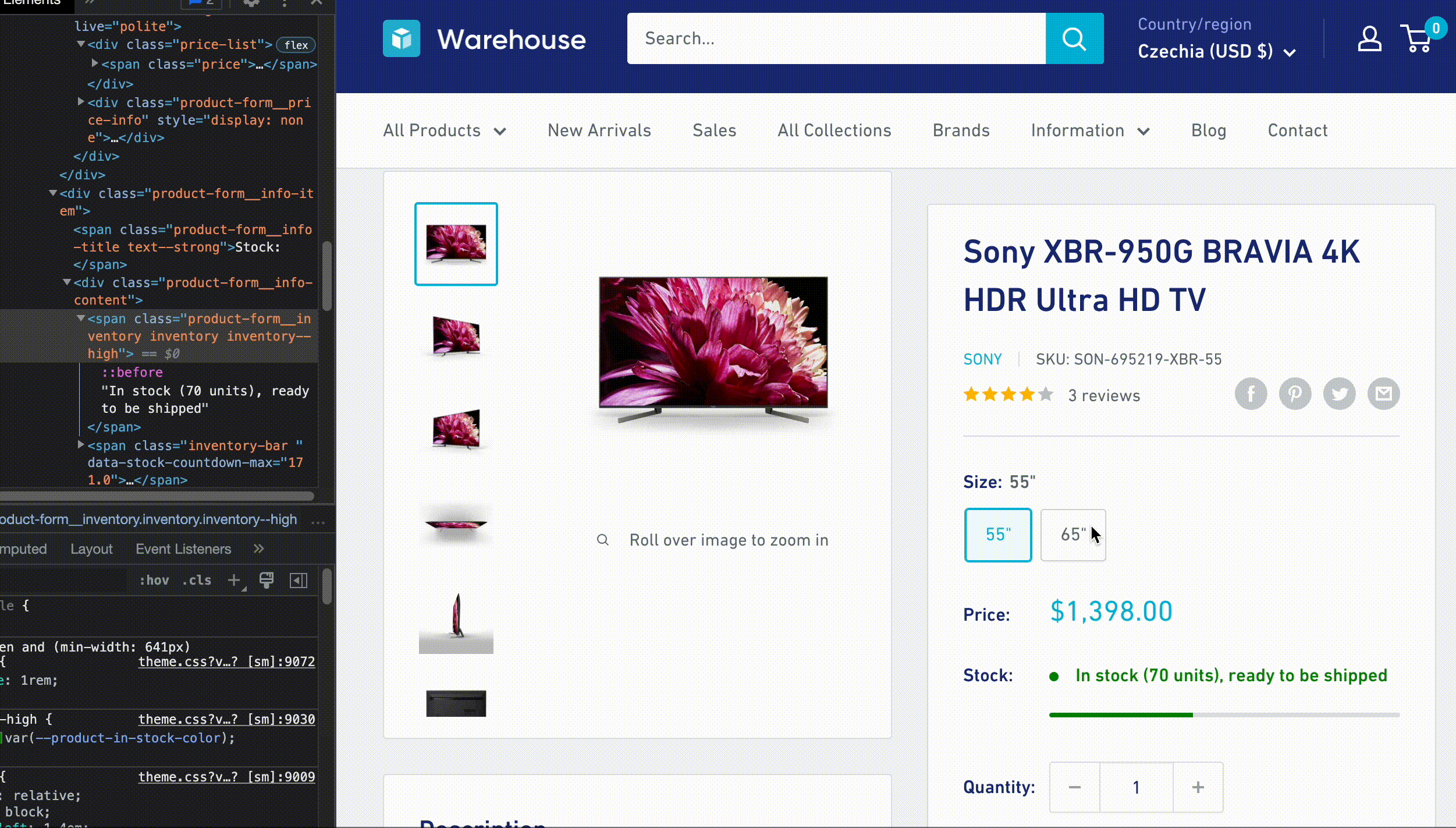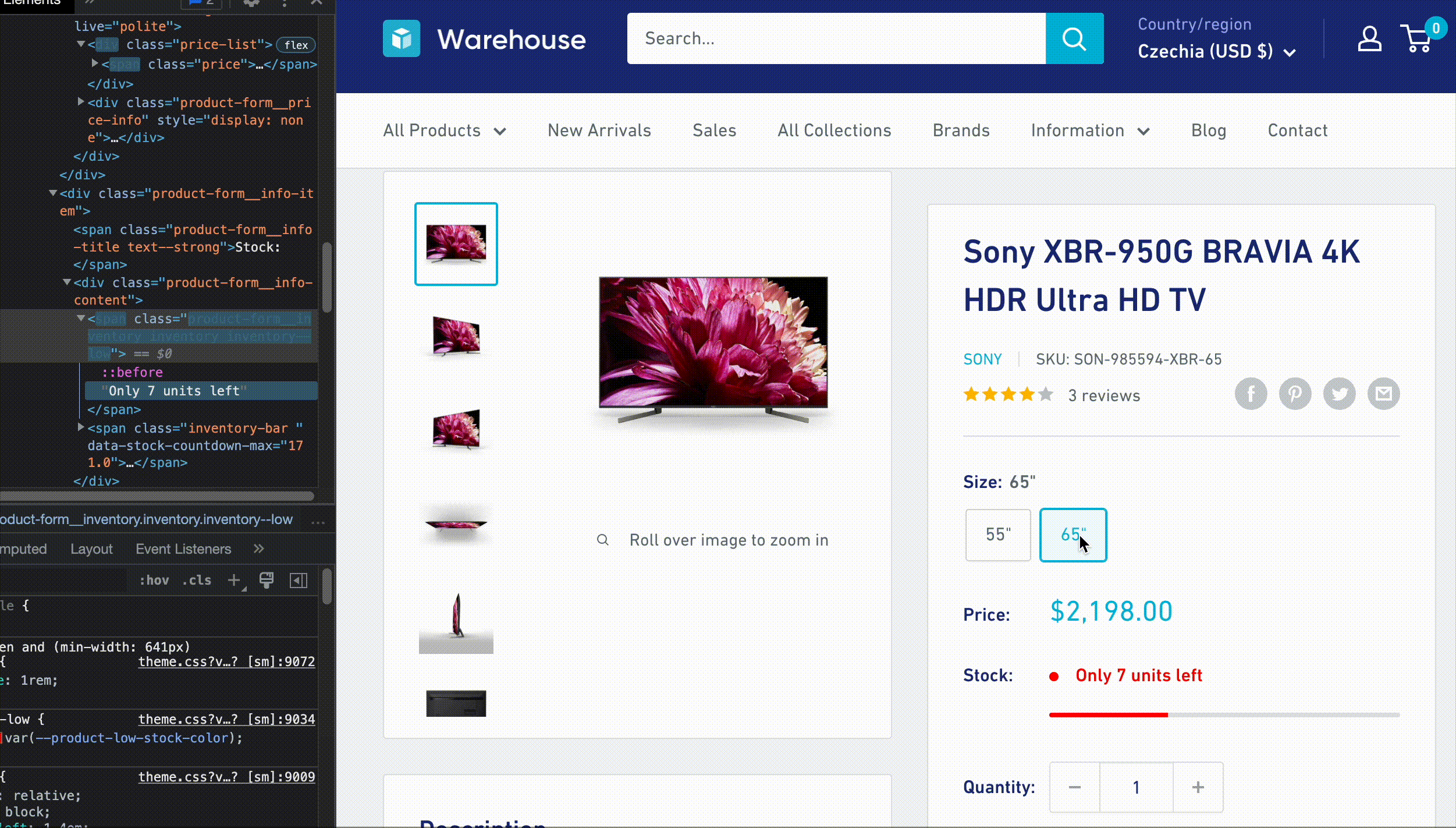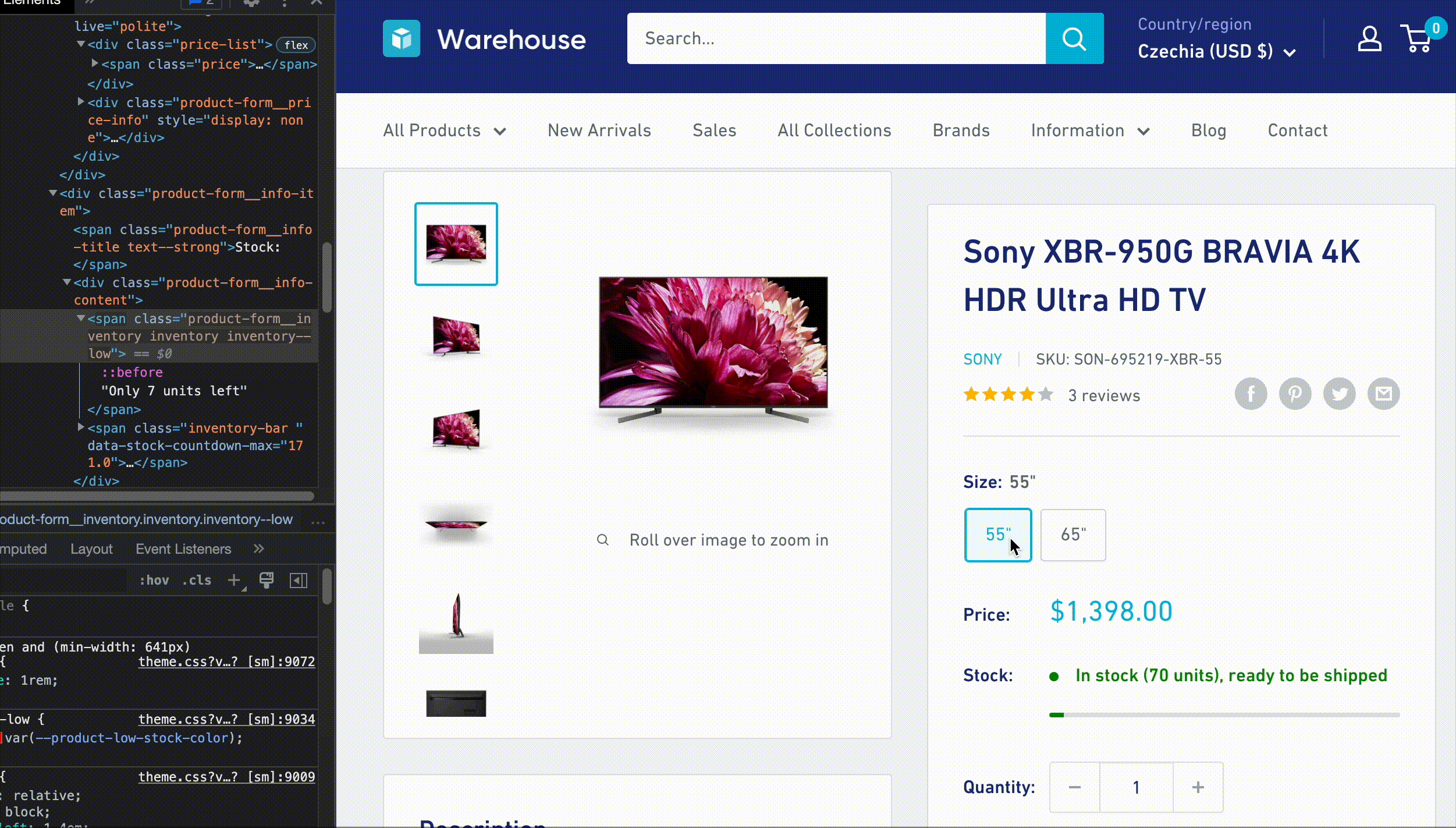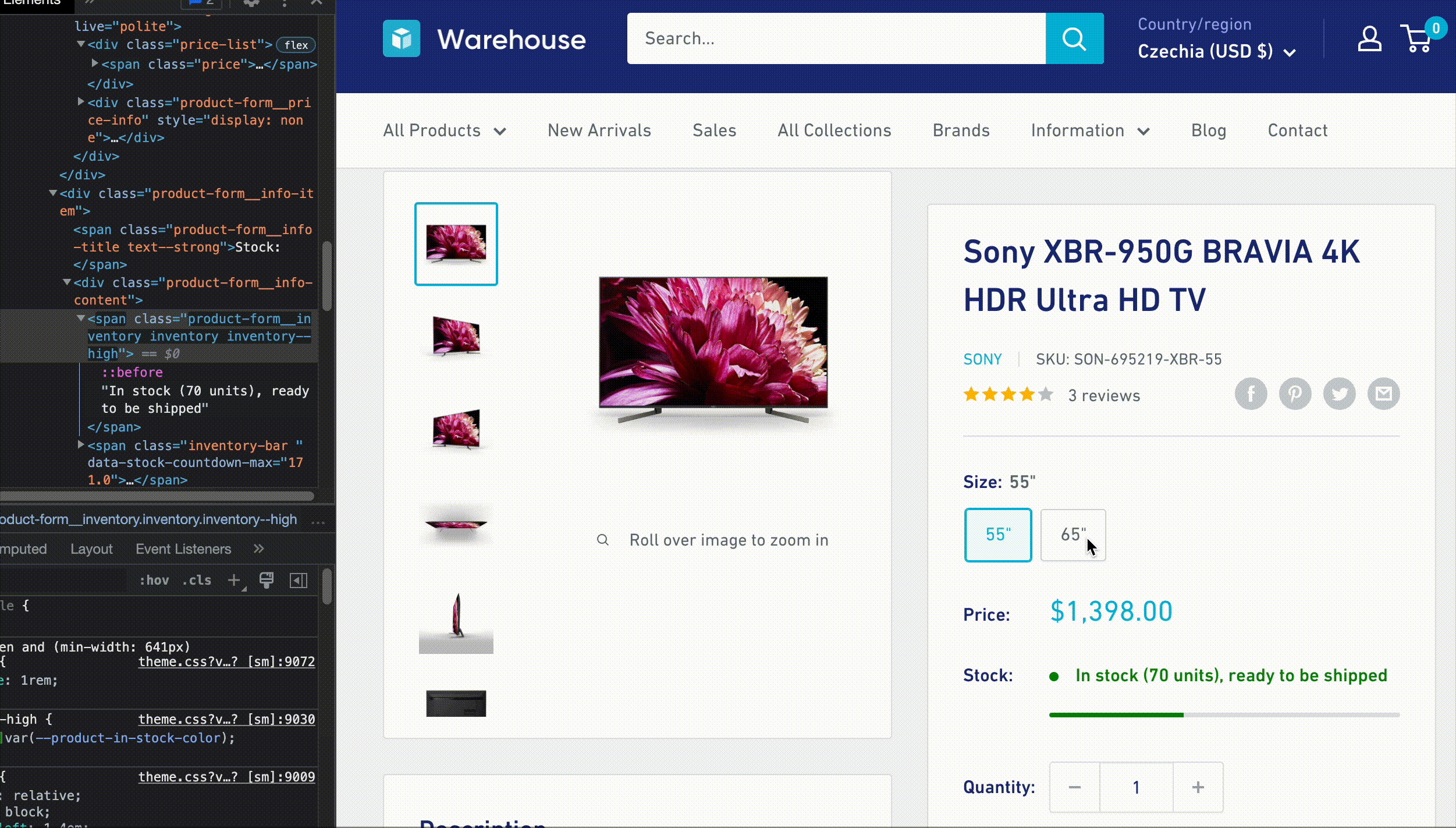
First, let's extract information about the variants. If we go to Sony XBR-950G BRAVIA and open the DevTools, we can see that the buttons for switching between variants look like this:
<div class="block-swatch-list">
<div class="block-swatch">
<input class="block-swatch__radio product-form__single-selector is-filled" type="radio" name="template--14851594125363__main-1916221128755-1" id="template--14851594125363__main-1916221128755-1-1" value="55"" checked="" data-option-position="1">
<label class="block-swatch__item" for="template--14851594125363__main-1916221128755-1-1" title="55"">
<span class="block-swatch__item-text">55"</span>
</label>
</div>
<div class="block-swatch">
<input class="block-swatch__radio product-form__single-selector" type="radio" name="template--14851594125363__main-1916221128755-1" id="template--14851594125363__main-1916221128755-1-2" value="65"" data-option-position="1">
<label class="block-swatch__item" for="template--14851594125363__main-1916221128755-1-2" title="65"">
<span class="block-swatch__item-text">65"</span>
</label>
</div>
</div>
Nice! We can extract the variant names, but we also need to extract the price for each variant. Switching the variants using the buttons shows us that the HTML changes dynamically. This means the page uses JavaScript to display this information.
If we can't find a workaround, we'd need our scraper to run browser JavaScript. That's not impossible. Scrapers can spin up their own browser instance and automate clicking on buttons, but it's slow and resource-intensive. Ideally, we want to stick to plain HTTP requests and Cheerio as much as possible.
After a bit of detective work, we notice that not far below the block-swatch-list there's also a block of HTML with a class no-js, which contains all the data!
<div class="no-js product-form__option">
<label class="product-form__option-name text--strong" for="product-select-1916221128755">Variant</label>
<div class="select-wrapper select-wrapper--primary is-filled">
<select id="product-select-1916221128755" name="id">
<option value="17550242349107" data-sku="SON-695219-XBR-55">
55" - $1,398.00
</option>
<option value="17550242414643" data-sku="SON-985594-XBR-65" selected="selected">
65" - $2,198.00
</option>
</select>
</div>
</div>
These elements aren't visible to regular visitors. They're there just in case browser JavaScript fails to work, otherwise they're hidden. This is a great find because it allows us to keep our scraper lightweight.
Extracting variants
Using our knowledge of Cheerio, we can locate the option elements and extract the data we need. We'll loop over the options, extract variant names, and create a corresponding array of items for each product:
const listingURL = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const $ = await download(listingURL);
const promises = $(".product-item").toArray().map(async element => {
const $productItem = $(element);
const item = parseProduct($productItem, listingURL);
const $p = await download(item.url);
item.vendor = $p(".product-meta__vendor").text().trim();
const $options = $p(".product-form__option.no-js option");
const items = $options.toArray().map(optionElement => {
const $option = $(optionElement);
const variantName = $option.text().trim();
return { variantName, ...item };
});
return item;
});
const data = await Promise.all(promises);
The CSS selector .product-form__option.no-js targets elements that have both the product-form__option and no-js classes. We then use the descendant combinator to match all option elements nested within the .product-form__option.no-js wrapper.
We loop over the variants using .map() method to create an array of item copies for each variantName. We now need to pass all these items onward, but the function currently returns just one item per product. And what if there are no variants?
Let's adjust the loop so it returns a promise that resolves to an array of items instead of a single item. If a product has no variants, we'll return an array with a single item, setting variantName to null:
const listingURL = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const $ = await download(listingURL);
const promises = $(".product-item").toArray().map(async element => {
const $productItem = $(element);
const item = parseProduct($productItem, listingURL);
const $p = await download(item.url);
item.vendor = $p(".product-meta__vendor").text().trim();
const $options = $p(".product-form__option.no-js option");
const items = $options.toArray().map(optionElement => {
const $option = $(optionElement);
const variantName = $option.text().trim();
return { variantName, ...item };
});
return items.length > 0 ? items : [{ variantName: null, ...item }];
});
const itemLists = await Promise.all(promises);
const data = itemLists.flat();
After modifying the loop, we also updated how we collect the items into the data array. Since the loop now produces an array of items per product, the result of await Promise.all() is an array of arrays. We use .flat() to merge them into a single, non-nested array.
If we run the program now, we'll see 34 items in total. Some items don't have variants, so they won't have a variant name. However, they should still have a price set—our scraper should already have that info from the product listing page.
[
...
{
"variantName": null,
"url": "https://warehouse-theme-metal.myshopify.com/products/klipsch-r-120sw-powerful-detailed-home-speaker-set-of-1",
"title": "Klipsch R-120SW Powerful Detailed Home Speaker - Unit",
"minPrice": 32400,
"price": 32400,
"vendor": "Klipsch"
},
...
]
Some products will break into several items, each with a different variant name. We don't know their exact prices from the product listing, just the min price. In the next step, we should be able to parse the actual price from the variant name for those items.
[
...
{
"variantName": "Red - $178.00",
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xb950-extra-bass-wireless-headphones-with-app-control",
"title": "Sony XB-950B1 Extra Bass Wireless Headphones with App Control",
"minPrice": 12800,
"price": null,
"vendor": "Sony"
},
{
"variantName": "Black - $178.00",
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xb950-extra-bass-wireless-headphones-with-app-control",
"title": "Sony XB-950B1 Extra Bass Wireless Headphones with App Control",
"minPrice": 12800,
"price": null,
"vendor": "Sony"
},
...
]
Perhaps surprisingly, some products with variants will have the price field set. That's because the shop sells all variants of the product for the same price, so the product listing shows the price as a fixed amount, like $74.95, instead of from $74.95.
[
...
{
"variantName": "Red - $74.95",
"url": "https://warehouse-theme-metal.myshopify.com/products/jbl-flip-4-waterproof-portable-bluetooth-speaker",
"title": "JBL Flip 4 Waterproof Portable Bluetooth Speaker",
"minPrice": 7495,
"price": 7495,
"vendor": "JBL"
},
...
]
Parsing price
The items now contain the variant as text, which is good for a start, but we want the price to be in the price property. Let's introduce a new function to handle that:
function parseVariant($option) {
const [variantName, priceText] = $option
.text()
.trim()
.split(" - ");
const price = parseInt(
priceText
.replace("$", "")
.replace(".", "")
.replace(",", "")
);
return { variantName, price };
}
First, we split the text into two parts, then we parse the price as a number. This part is similar to what we already do for parsing product listing prices. The function returns an object we can merge with item.
Saving price
Now, if we use our new function, we should finally get a program that can scrape exact prices for all products, even if they have variants. The whole code should look like this now:
import * as cheerio from 'cheerio';
import { writeFile } from 'fs/promises';
import { AsyncParser } from '@json2csv/node';
async function download(url) {
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
return cheerio.load(html);
} else {
throw new Error(`HTTP ${response.status}`);
}
}
function parseProduct($productItem, baseURL) {
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const url = new URL($title.attr("href"), baseURL).href;
const $price = $productItem.find(".price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
return { url, title, ...priceRange };
}
async function exportJSON(data) {
return JSON.stringify(data, null, 2);
}
async function exportCSV(data) {
const parser = new AsyncParser();
return await parser.parse(data).promise();
}
function parseVariant($option) {
const [variantName, priceText] = $option
.text()
.trim()
.split(" - ");
const price = parseInt(
priceText
.replace("$", "")
.replace(".", "")
.replace(",", "")
);
return { variantName, price };
}
const listingURL = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const $ = await download(listingURL);
const promises = $(".product-item").toArray().map(async element => {
const $productItem = $(element);
const item = parseProduct($productItem, listingURL);
const $p = await download(item.url);
item.vendor = $p(".product-meta__vendor").text().trim();
const $options = $p(".product-form__option.no-js option");
const items = $options.toArray().map(optionElement => {
const variant = parseVariant($(optionElement));
return { ...item, ...variant };
});
return items.length > 0 ? items : [{ variantName: null, ...item }];
});
const itemLists = await Promise.all(promises);
const data = itemLists.flat();
await writeFile('products.json', await exportJSON(data));
await writeFile('products.csv', await exportCSV(data));
Let's run the scraper and see if all the items in the data contain prices:
[
...
{
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xb950-extra-bass-wireless-headphones-with-app-control",
"title": "Sony XB-950B1 Extra Bass Wireless Headphones with App Control",
"minPrice": 12800,
"price": 17800,
"vendor": "Sony",
"variantName": "Red"
},
{
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xb950-extra-bass-wireless-headphones-with-app-control",
"title": "Sony XB-950B1 Extra Bass Wireless Headphones with App Control",
"minPrice": 12800,
"price": 17800,
"vendor": "Sony",
"variantName": "Black"
},
...
]
Success! We managed to build a Node.js application for watching prices!
Is this the end? Maybe! In the next lesson, we'll use a scraping framework to build the same application, but with less code, faster requests, and better visibility into what's happening while we wait for the program to finish.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Build a scraper for watching npm packages
You can build a scraper now, can't you? Let's build another one! From the registry at npmjs.com, scrape information about npm packages that match the following criteria:
- Have the keyword "LLM" (as in large language model)
- Updated within the last two years ("2 years ago" is okay; "3 years ago" is too old)
Print an array of the top 5 packages with the most dependents. Each package should be represented by an object containing the following data:
- Name
- Description
- URL to the package detail page
- Number of dependents
- Number of downloads
Your output should look something like this:
[
{
name: 'langchain',
url: 'https://www.npmjs.com/package/langchain',
description: 'Typescript bindings for langchain',
dependents: 735,
downloads: 3938
},
{
name: '@langchain/core',
url: 'https://www.npmjs.com/package/@langchain/core',
description: 'Core LangChain.js abstractions and schemas',
dependents: 730,
downloads: 5994
},
...
]
Solution
After inspecting the registry, you'll notice that packages with the keyword "LLM" have a dedicated URL. Also, changing the sorting dropdown results in a page with its own URL. We'll use that as our starting point, which saves us from having to scrape the whole registry and then filter by keyword or sort by the number of dependents.
import * as cheerio from 'cheerio';
async function download(url) {
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
return cheerio.load(html);
} else {
throw new Error(`HTTP ${response.status}`);
}
}
const listingURL = "https://www.npmjs.com/search?page=0&q=keywords%3Allm&sortBy=dependent_count";
const $ = await download(listingURL);
const promises = $("section").toArray().map(async element => {
const $card = $(element);
const details = $card
.children()
.first()
.children()
.last()
.text()
.split("•");
const updatedText = details[2].trim();
const dependents = parseInt(details[3].replace("dependents", "").trim());
if (updatedText.includes("years ago")) {
const yearsAgo = parseInt(updatedText.replace("years ago", "").trim());
if (yearsAgo > 2) {
return null;
}
}
const $link = $card.find("a").first();
const name = $link.text().trim();
const url = new URL($link.attr("href"), listingURL).href;
const description = $card.find("p").text().trim();
const downloadsText = $card
.children()
.last()
.text()
.replace(",", "")
.trim();
const downloads = parseInt(downloadsText);
return { name, url, description, dependents, downloads };
});
const data = await Promise.all(promises);
console.log(data.filter(item => item !== null).splice(0, 5));
Since the HTML doesn't contain any descriptive classes, we must rely on its structure. We're using .children() to carefully navigate the HTML element tree.
For items older than 2 years, we return null instead of an item. Before printing the results, we use .filter() to remove these empty values and .splice() the array down to just 5 items.
Find the shortest CNN article which made it to the Sports homepage
Scrape the CNN Sports homepage. For each linked article, calculate its length in characters:
- Locate the element that holds the main content of the article.
- Use
.text()to extract all the content as plain text. - Use
.lengthto calculate the character count.
Skip pages without text (like those that only have a video). Sort the results and print the URL of the shortest article that made it to the homepage.
At the time of writing, the shortest article on the CNN Sports homepage is about a donation to the Augusta National Golf Club, which is just 1,642 characters long.
Solution
import * as cheerio from 'cheerio';
async function download(url) {
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
return cheerio.load(html);
} else {
throw new Error(`HTTP ${response.status}`);
}
}
const listingURL = "https://edition.cnn.com/sport";
const $ = await download(listingURL);
const promises = $(".layout__main .card").toArray().map(async element => {
const $link = $(element).find("a").first();
const articleURL = new URL($link.attr("href"), listingURL).href;
const $a = await download(articleURL);
const content = $a(".article__content").text().trim();
return { url: articleURL, length: content.length };
});
const data = await Promise.all(promises);
const nonZeroData = data.filter(({ url, length }) => length > 0);
nonZeroData.sort((a, b) => a.length - b.length);
const shortestItem = nonZeroData[0];
console.log(shortestItem.url);